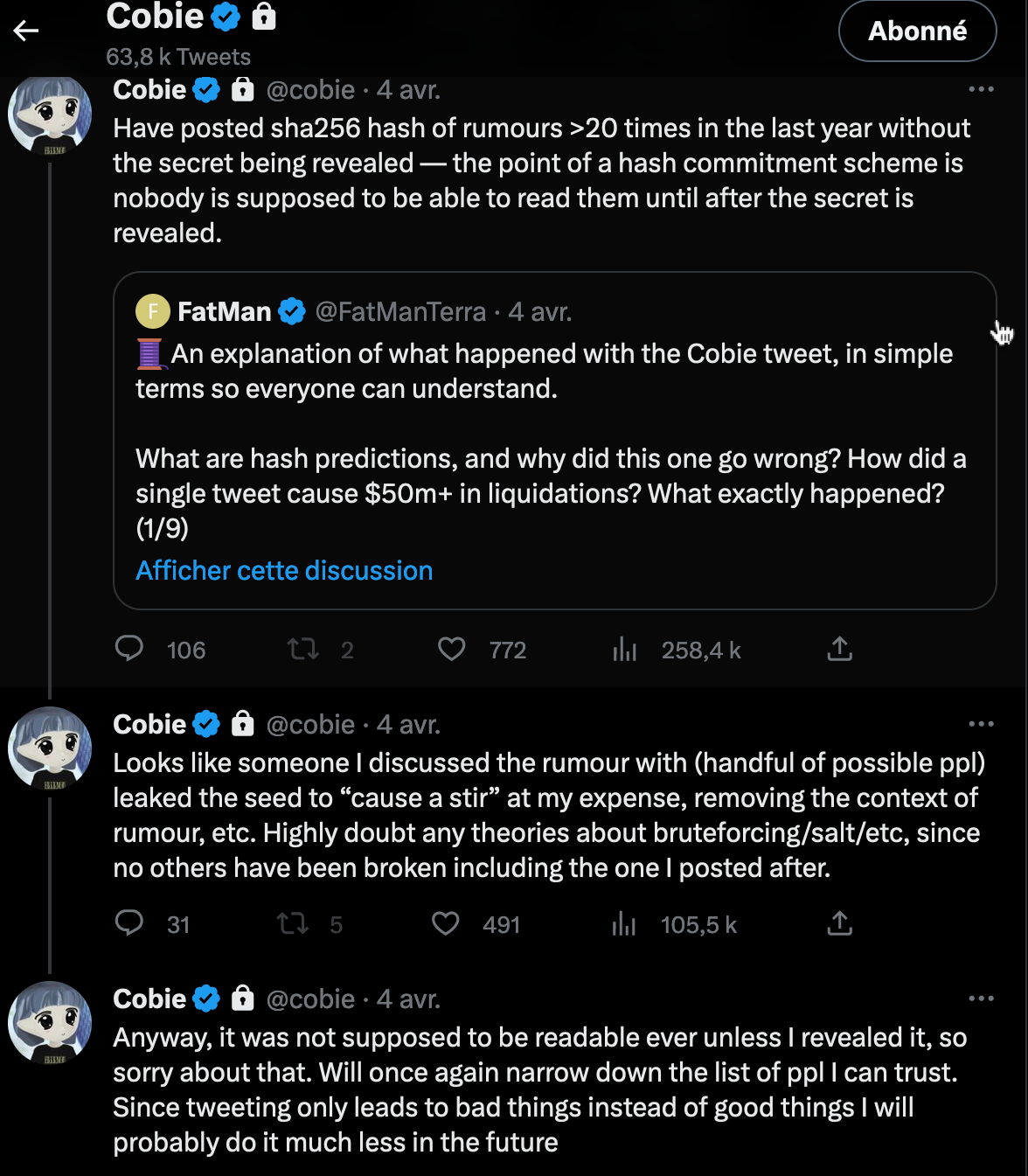
This story starts from a tweet, as a lot of stories in Crypto(currencies). @cobie tweeted the hash of a message, like he has done numerous times in the past.

This turns out to be:
SHA256("Interpol Red Notice for CZ")
0xefedf7c4a51516ef909fb0a1c11e7443ee8cf85727d3ec14d0b7c3682e4a2bb6
This started a ripple effect on the crypto market, because Cobie is seen as trustworthy in the cryptospace, and because it meant that CZ, the CEO of Binance, was under much more trouble than what is already assumed. This part of the story does not interest me. What really got my attention was people assuming, from the message, that the commit was easy to crack and reveal. Let us explore how one tackles such task and estimate the difficulty.
Cryptographic Hash Functions
I can recommend the course by Dan Boneh on hash functions in this crypto MOOC. You can watch his actual cryptographic class if you want to dive deeper in that subject. For us today, we will stay at a high level.
A cryptographic hash function is an algorithm that gives you the fingerprint, digest, of some data, the same way I can identify you by your fingerprints or your DNA. They have some the interesting properties:
- They are quick to compute. Usually you can easily compute way over 100K H/s.
- The output has a fixed size, while there is no restriction on the input. e.g. SHA256 returns a hash 256 bits long.
- They are collision resistant. There are various collision attacks which we won’t go into details. But basically this implies that you cannot “inverse” the hash easily, even if you know more details on the input like the data type.
Small note: I saw some news articles about this subject speaking about hash as some sort of encryption. IT IS NOT (Coindesk,The Block, you guys should know better). What Cobie did is call a commit-reveal scheme. It is not blinded though (more on this and salt later) as anyone with the exact message will get the same commit.
We give here an idea of the speed of those operations, using the OpenSSL benchmark on my MAC.
% openssl speed sha256
Doing sha256 for 3s on 16 size blocks: 7810017 sha256's in 3.00s
Doing sha256 for 3s on 64 size blocks: 4796663 sha256's in 3.00s
Doing sha256 for 3s on 256 size blocks: 2393897 sha256's in 2.99s
Doing sha256 for 3s on 1024 size blocks: 795097 sha256's in 3.00s
Doing sha256 for 3s on 8192 size blocks: 109679 sha256's in 3.00s
LibreSSL 3.3.6
built on: date not available
options:bn(64,64) rc4(16x,int) des(idx,cisc,16,int) aes(partial) blowfish(idx)
compiler: information not available
The 'numbers' are in 1000s of bytes per second processed.
type 16 bytes 64 bytes 256 bytes 1024 bytes 8192 bytes
sha256 41665.74k 102398.41k 204716.62k 271636.59k 299624.33k
Which gives less than 2 MH/S (4796663/3s) if I only look at 64 bytes messages(or 100MB/S hashing bandwidth - see explanation for openssl bench). If you assume that the inputs are in ASCII (English words, 1 Byte per character) or maybe Unicode (1-2 Bytes), that gives 32-64 characters max in our messages. That is the estimation to target Cobie’s message which is 26 characters long.
Cracking is a challenge in cryptography/cybersecurity that is embarrassingly parallelizable and is well suited to powerful GPUs. I remembered, while doing research for this article, dreaming about building my own version of this Password Cracking monster with 8x NVIDIA GTX 1080 Ti GPUs. It had a whooping Speed.Dev.#*…..: 37093.2 MH/s speed with the tool hashcat. Today, I looked for what was the best GPU and according to [this article](https://www.pcgamer.com/the-best-graphics-cards/, the Nvidia GeForce RTX 4090 is unmatched. So how fast is it? 21975.5 MH/s. The price of the card is around $2000 and 100GH/s would start at $15K (napkin estimate). If anyone is feeling generous…😅
Wordlists
When you try to crack the code, you usually have 2 steps:
- Build the code candidates
- Test those candidates
In the second step, your target can be a well know function, like a secure password storage like PBKDF2, scrypt or Argon2, or in this case just a plain SHA256. The target can also be some peculiar function, like a wallet encryption scheme, although now they are more common, or reversing 0x78e111f6, the infamous solidity signature of an MEV bot that I tried not long ago. If you are lucky, there is a very optimized tool (hashcat…) for it and you just need to figure out how to use it best. If not, you have to build it in the most efficient way you can, using your favorite language, the lower the level the better. You could do C/C++ for CPU, CUDA for GPU, some Rust if you are modern, Python for usability and hacker tooling more than performance. Go is my go-to language because it is easier to develop and iterate quickly and I love using goroutines. But that is a topic for another day.
In the first step, on one end you have bruteforcing, where you attempt to test all the possible candidates. For a four digits pin code, you will try from 0000 to 9999. On the other end, you can have a list of candidates tailored to your target, through social engineering data collection. Like I might know that you are a huge tennis fan and your pin code is most likely the score of a game ( try yourself with exercise 8: Hack me if you can).
How big should my wordlist be?
I managed to find again a good repertory for wordlists that I used some years ago: https://weakpass.com.
Their complete wordlist, weakpass_3a, has 9.7 billion words in it. Assuming I have the 100GH/s firepower, I can test the hash of each word in the lists and be done in 0.1s. But we know we are targeting a sentence, with at least >1 word. I won’t be done any time soon (9.7 billion * 9.7 billion / 100 billion H/s). Also each word could have been written with some variations. For example notice how Notice is capitalized while for isn’t and CZ use only capital letters. Beyond the everyday day English and Cobie’s vocabulary, you need more context specific content. The more specific, the better. This is why hacking starts by learning as much as possible from your target.
“Bigger” is not better, “more accurate” is!
There is a theoretical limit you need to be aware of. In cryptography, we said a scheme is secure if it requires, per the best attack, >=2^80 steps to break it. The limit of your cracking setup will be much lower of course, hopefully even for state agencies like the NSA. For convenience in our estimations, let us use
2^10=1024 ~ ~ 1000 = 10^3
=> 2^80 = 2^(10*8) ~ 10^(3*8)=10^24
10^24 underestimates that limit but this is fine for our quick calculations. This means that if we have a dictionary 1 million words long (10^6), 4 words is intractable for us. It would take us (rounding everything to power of 10 because I’m not a 🤖)
10^24/10^11= 10^13 seconds >10^8 days > 10^5 years
Let us estimate in the reverse way: what is the size of the wordlist we can build if we are going to run hashcat for 10 days?
For this period, our search will go over 10 days * 100000 s/days * 10^11 H/s = 10^17 SHA256 Hashes. We know (now) that the answer is 5 words long which gives us a length (10^(17/5)) in the [1000;10000] interval.
Reviewing what we could guess
It is very hard to not have a biased view of the content of the wordlist because we know the solution. There is no way to really prove how you found the pre-image of that hash, all we know is that you know it. So what I am trying to do here is present how I feel I would have made my assumptions. It doesn’t mean someone else couldn’t have narrowed down the possibilities much more accurately. I am saying I don’t think this is likely and I will try to convey that as fairly as possible.
What we know
- Cobie speaks English, specifically he is British.
- He usually write a ASCII text and there shouldn’t be any weird emoji/symbol/… (remember it is a commit, not a password).
- The sentence is not long. (You won’t break it if it’s too long anyway).
- It is crypto related. If not, then it doesn’t interest us anyway.
- There shouldn’t be writing mistakes: typo, two spaces instead of one between words… Cobie did delete a previous tweet-hash-commit-thingy because he said there was a typo. https://twitter.com/cobie/status/1642926123695882241
What we could have guessed
- The words have appeared in crypto headline, Cobie’s tweets, UpOnly (his podcast) transcripts
- Recent news related. I am not sure I would have thought of Binance first but they were in the news very recently. Also some people were spreading those rumors before Cobie. Not to me though.
- No weird capitalization, like in the middle of the word: no cap, all cap or just first letter. I will admit that I would have tried a simple sentence structure: First letter of the sentence and names capitalized, everything else lower cap. No punctuation.
What was hard
- the combination of capitalization for, Notice, CZ. That would have thrown me off. Even taking the simple no cap, all cap or just first letter, that is 3x the number of steps.
- I feel like I would have very low chances to have Interpol in my dictionary while CZ would have been OK.
- There is a lot of content from Cobie to parse. (Although he spends a lot of time being mean to Ledger and laughing on UpOnly😜).
- Any other uncertainty you have add more tests to be done.
Some numbers for thought
- Coingecko tracks 10925 coins at the time of writing. Where do we draw the line for the coins that are interesting to talk about?
- A tweet is (used to be) max 280 characters. 100 of those should give you more than 1000 unique words. What about 10K unique words?
- A quick glance at TheBlock and Coindesk gives the impression that headlines are more than 10 words long. Headlines should cover most memes & main characters right? (insert “right?right?” meme in your head)
- Now you can add UpOnly transcripts but those episodes are often over 2 hours long. I found some transcripts here and the word count on one was +20K words and +2K unique ones.
Can you crack it? Most likely Nope
I have a really hard time seeing how one could be accurate without the size of the trials growing too much. From what I laid out, staying below a 10K long wordlist, which is already big, is a challenge. You would have needed a good amount of luck or insight to tailor your cracking. Personally, I can try my hands on reversing that hash if you can give me a budget for 10 of those beast cracking machines. Looking at the price action, that would have been a very good trade, highly unlikely though.
This is certainly not an easy challenge to tackle, despite what people were saying online.
Some of their wrong assumptions:
- Many people were working on it. It doesn’t seem that reversing Cobie’s hashes would be much of alpha. But this might prove the inverse.
- Also that distributed work was efficient without any apparent coordination.
- They underestimated how fast we can hash. Which is OK after all.
- But they badly underestimated how huge the dictionary/wordlist would be. They thought the list of candidates was small enough so that the task was tractable.
The most likely explanation is that someone leaked it. Or maybe someone had seen the rumor before and could have made educated guesses.
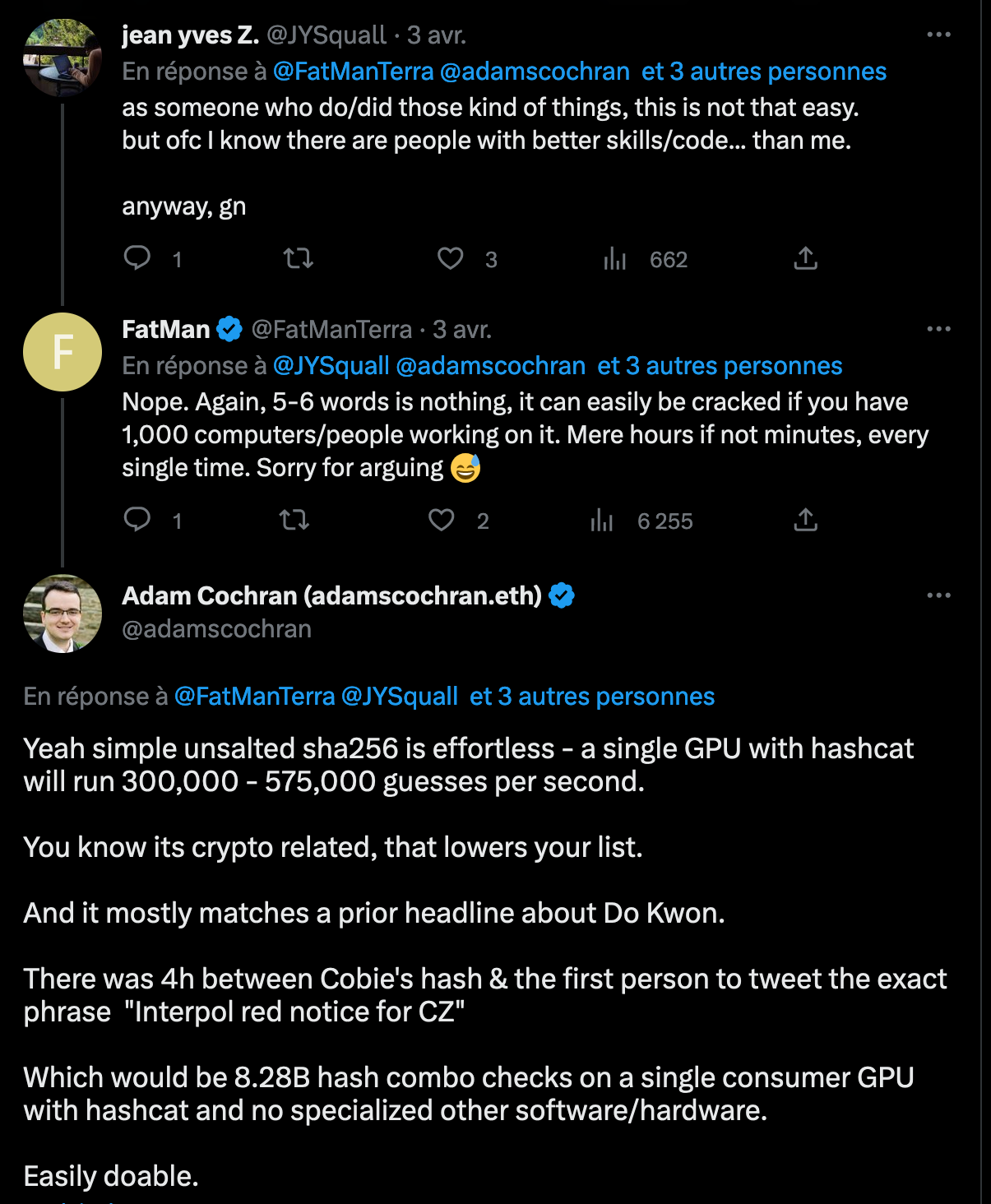
Remarks
There were some mentions of salt. In cryptography, the salt is randomness you add to the password, specific to each user, so that the hash would be different. This implies that you need to run your attack against each user, even if they have the same password. For Password storage, salts are not required to be hidden. In our case, the goal is to do a commit-reveal and what you would want to add is some randomness (that you keep secret) so that I have no chance to guess the message. Having this randomness means it’s Game Over. But I hope you are convinced now that this was not necessary here. Maybe it will be a good idea to add some from now on or to write at least one word weirdly Cobie.
Another way, more web3 if you will, to do this would be to explore using Zero Knowledge cryptography on a Dapp linked to your Metamask or other Ethereum wallet. This might be a nice hackathon idea if no one has it out yet. A quick search showed that this subject is called Commit-and-Prove Zero-Knowledge Proof Systems.
As for me, after being annoyed by all the “this is easy” comments, it was nice to sit down and reflect on how I would actually crack this hash. There are some blindspots you can have if you don’t give it a try, like how you really have to make sure that you are going over all your message candidates and monitor the processes. It is also good to have benchmarks data to have a sense at how (in)practical things can get.
That’s it for me! Feel free to reach out if you have comments or questions.
Jean Yves Z.